DeepSeek开源周开源了多个项目,并且在开源周结束之后,还发布DeepSeek-V3 / R1 推理系统概览 ,网络上很多人关心的是其公布的成本利润细节, 但是个人认为文章中介绍的推理系统的优化目标和解决方案也值得关注.
根据文章中介绍的内容,可以很好的理解DeepSeek开源周中开源的项目是为了什么目的而开发的,在整个系统中发挥了什么作用.
零. MoE 混合专家模型
要理解为什么DeepSeek使用的方案是大规模节点专家并行(Epert Paralleism/ EP),需要先了解DeepSeek使用的大模型架构.
DeepSeek 使用的是混合专家模型(Mixture of Experts:MoE)是一种稀疏门控制的深度学习模型,它主要由一组专家模型和一个门控模型组成。MoE的基本理念是将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配一个或多个专家模型。每个专家模型可以专注于处理输入这部分数据,从而提高模型的整体性能。
关于MoE可以参考:混合专家模型 (MoE) 详解
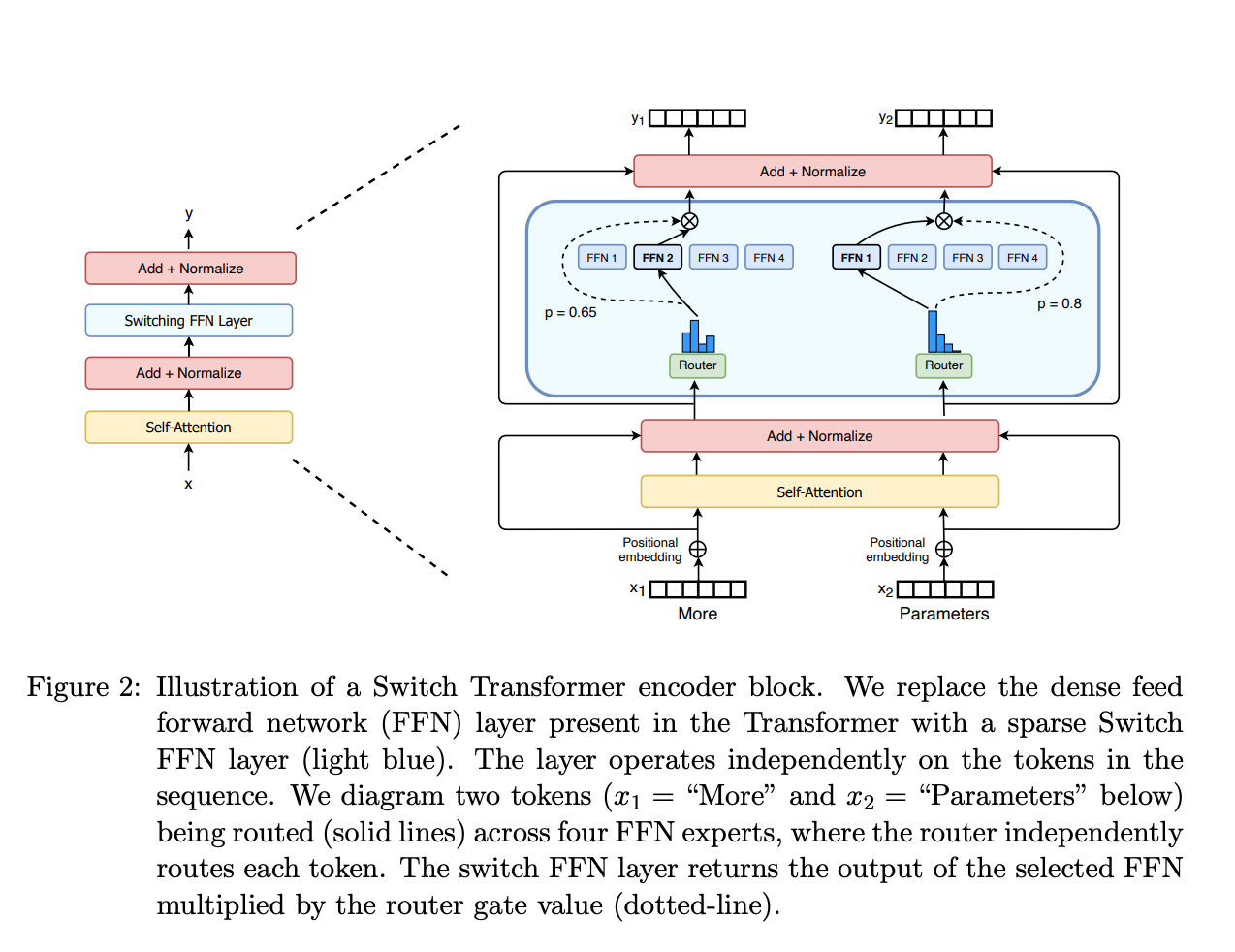
简单来讲, MoE中包含了一组专业化子模型(专家), 每个专家负责在其擅长的领域内做出贡献. 模型处理一个token的时候, 由门控模型决定由哪些专家来处理, 通常只会交给其中少数的几个专家来处理.
一. DeepSeek-V3/R1 推理系统概览
了解了MoE之后,再来看DeepSeek-V3 / R1 推理系统概览 就比较好理解DeepSeek为什么采用EP的方案了
DeepSeek的模型中包含了大量的专家,一个并行方法就是专家并行(Expert Parallelism EP): 专家被放置在不同的节点上。如果与数据并行结合,每个节点拥有不同的专家,数据在所有节点之间分割。
DeepSeek-V3/R1 推理系统的优化目标是:更大的吞吐,更低的延迟。
为了实现这两个目标,我们的方案是使用大规模跨节点专家并行(Expert Parallelism / EP)。首先 EP 使得 batch size 大大增加,从而提高 GPU 矩阵乘法的效率,提高吞吐。其次 EP 使得专家分散在不同的 GPU 上,每个 GPU 只需要计算很少的专家(因此更少的访存需求),从而降低延迟。
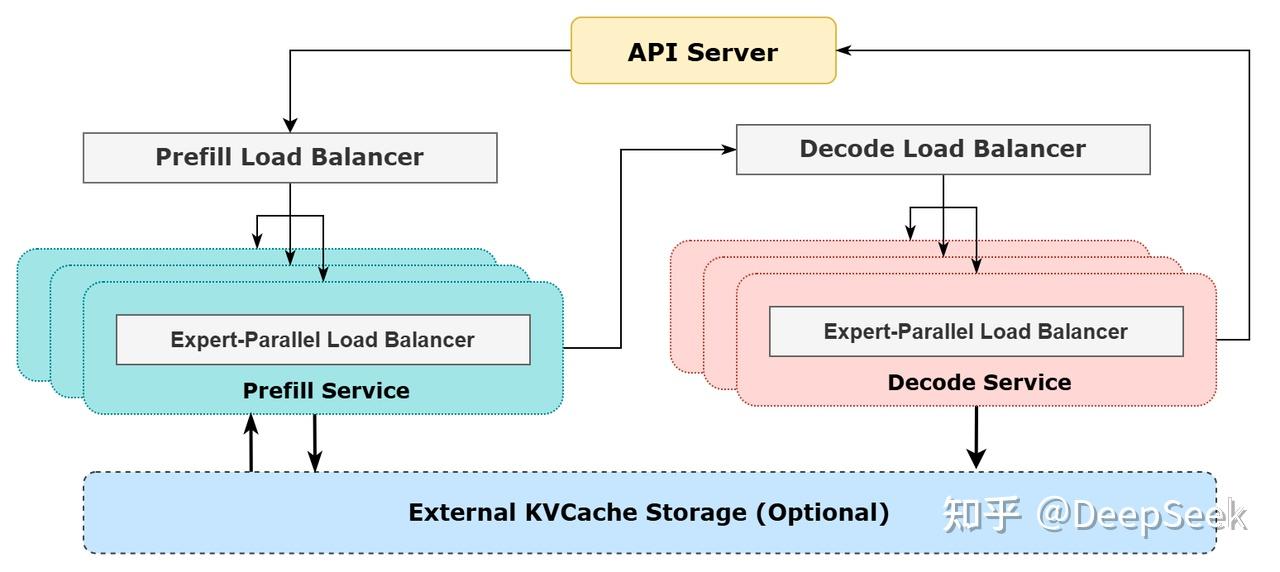
但是使用EP增加了系统的复杂度,所以DeepSeek采用了各种手动进行优化,以实现更大吞吐,更低延迟的目的:
- 计算通信重叠
- prefill阶段:两个 batch 的计算和通信交错进行
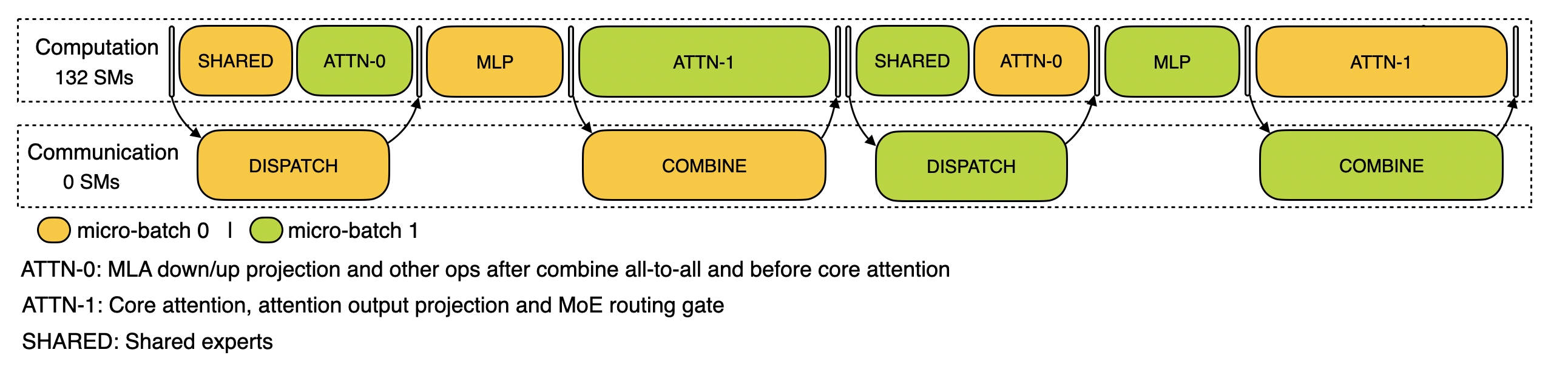
- decode阶段:不同阶段的执行时间有所差别,所以我们把 attention 部分拆成了两个 stage,共计 5 个 stage 的流水线来实现计算和通信的重叠
- 尽可能地负载均衡
- Prefill Load Balancer: 目标:各GPU的计算量尽量相同(core-attention 计算负载均衡),输入的token数量也尽量相同(dispatch 发送量负载均衡)
- Decode Load Balancer: 各GPU的KVCache占用量尽量相同(core-attention 计算负载均衡),请求数量尽量相同(dispatch 发送量负载均衡)
- Expert-Parallel Load Balancer: 目标:每个GPU上的专家计算量均衡(即最小化所有 GPU 的 dispatch 接收量的最大值)
二. DualPipe: 计算-通信阶段的完全重叠
GitHub地址: https://github.com/deepseek-ai/DualPipe
首先要处理的是计算通信重叠
多机多卡的专家并行会引入比较大的通信开销,所以我们使用了双 batch 重叠来掩盖通信开销,提高整体吞吐。
DualPipe is an innovative bidirectional pipeline parallelism algorithm introduced in the DeepSeek-V3 Technical Report . It achieves full overlap of forward and backward computation-communication phases, also reducing pipeline bubbles. For detailed information on computation-communication overlap, please refer to the profile data .
DualPipe实现了前向和后向的计算通信阶段的完全重叠,减少了管道气泡

下一个要处理的就是要实现尽可能的负载均衡
三. EPLB: 尽可能的负载均衡
GitHub地址: https://github.com/deepseek-ai/eplb
EPLB: Expert Parallelism Load Balancer
Deep Seek采用了一种 redundant experts的策略, 这种策略会复制任务繁重的专家(expert), 然后将这些重复的experts打包到GPU上以确保不同GPU上的负载均衡.
此外还使用group-limited expert routing, 尝试将同一组的expert放到同一节点上, 以减少节点间的数据流量
EPLB开源的负载均衡算法在仓库中的eblp.py文件中(是的,核心代码只有一个文件),该算法根据估计的专家负载计算出一个平衡的专家复制和放置计划, 但是没有公开预测专家负载的方法.

EPLB负载负载均衡算法包含两种策略以处理不同的场景:
- Hierarchical Load Balancing
- Global Load Balancing
具体算法细节建议去看原文和代码
四. DeepEP: 节点间的高效通信
在解决了节点的负载均衡问题之后, 下一个处理的问题是优化多节点之间的通信.
GitHub地址: https://github.com/deepseek-ai/DeepEP
DeepEP 是为专家混合 (MoE) 和专家并行 (EP) 量身定制的通信库. 提供了高吞吐和低延迟的all-to-all GPU 内核, 也称为MoE dispatch and combin.
DeepEP 还支持低精度运算, 包括FP8.
DeepEP为asymmetric-domain bandwidth forwarding 提供了一组内核优化, 例如数据从NVLink域(英伟达推出的一种总线及其通信协议, 用于CPU和GPU, GPU和GPU之间的通信)转发到RDMA域(Remote Direct Memory Access, 远程直接内存访问, 使计算机能直接访问远程计算机的内存). 此外还支持SM(Stream Multiprocessors) number control
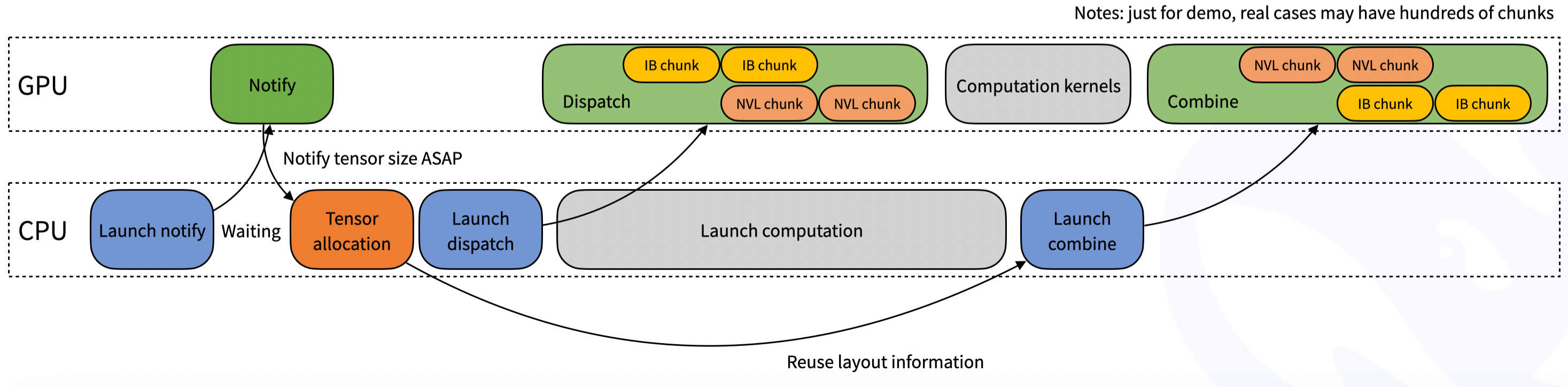
具体太专业了, 看不太懂, 希望有大佬能解释下. 总之就是性能很强, 实现了高吞吐和低延迟
五. Profiling Data in DeepSeek Infra
在开源DualPipe和EPLB的同一天, DeepSeek还开源了Profiling Data in DeepSeek Infra,
仓库地址: https://github.com/deepseek-ai/profile-data
开源的这个项目和之前的项目不一样, 没有代码, 而是训练和推理框架的分析数据. 不要觉得没代码就没价值, 这些性能数据展示了DeepSeek在训练和推理阶段的通信-计算重叠策略及底层实现细节, 有助于理解 DualPipe 和 DeepEP 等核心技术的工作原理.
Traning

Prefilling
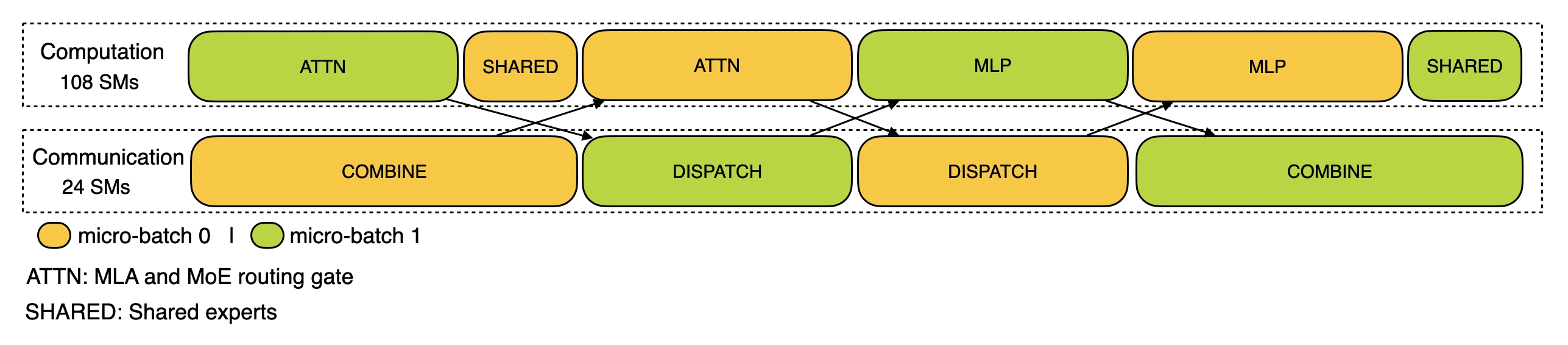
Decoding
六. FlashMLA: 更高效的推理效率
软件设计中处理复杂问题的一个常用手段是分层, 通过分层隐藏底层细节. 上面三个工具已经处理了在EP层面的优化任务了,但是继续深入, 进入到每个GPU执行的计算任务中, 还有很大的优化空间,.
DeepSeek开源周开源的工具不止包括了EP层的优化, 还包含了更底层的优化工具.
FlashMLA是一款针对英伟达Hopper架构GPU(如H100/H800)优化的高效MLA(Multi-Head Latent Attention)解码内核,旨在提升大语言模型(LLM)的推理效率,尤其在处理可变长度序列时表现突出
GitHub仓库: https://github.com/deepseek-ai/FlashMLA
DeepSeek 提到FlashMLA 的灵感来自 FlashAttention 2&3 和 cutlass 项目。FlashAttention 是一种高效的注意力计算方法,专门针对 Transformer 模型(如 GPT、BERT)的自注意力机制进行优化。它的核心目标是减少显存占用并加速计算。cutlass 也是一个优化工具,主要帮助提高计算效率。
现在的大模型很多都是用Transformer, 所以FlashMLA的开源意味着可以被集成到vLLM(高效 LLM 推理框架)Llama.cpp(轻量级 LLM 推理) 生态中, 从而让开源大模型(LLaMA, Mistral, Falcon)运行更高效.
实际上,在2月27号,vLLM
就宣布整合FlashMLA成功
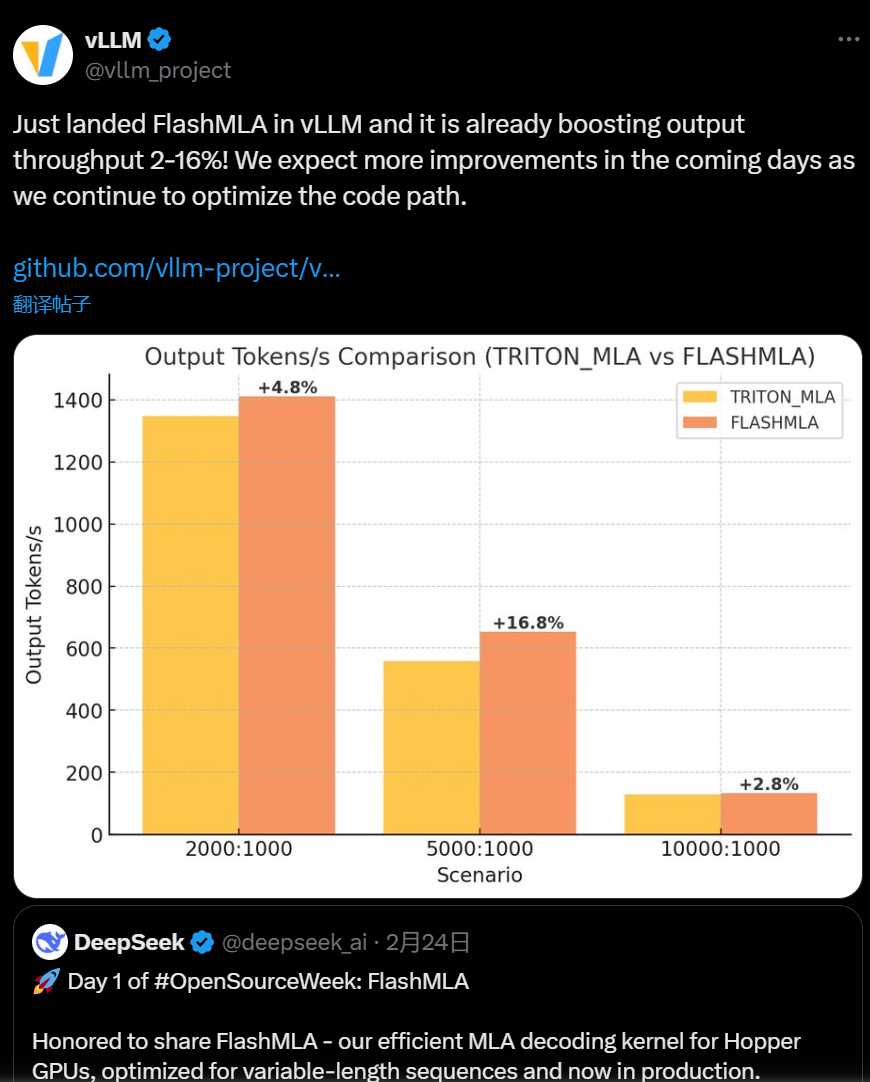
如果说前面的工具使针对Moe和EP实现的优化工具, 那么FlashMLA更加通用, 是对TransFormer的优化, 对所有使用到TransFormer的模型都有非常大的提升.
七. DeepGEMM: 优雅强大的矩阵乘法库
GitHub地址: https://github.com/deepseek-ai/DeepGEMM
DeepGEMM是一个针对FP8精度优化的矩阵乘法库(General Matrix Multiplications GEMMs),通过动态标度因子校准和CUDA核心指令级重写,解决低精度计算中的数值溢出问题。支持MoE模型的分组GEMM,实现专家权重的高效激活。
DeepGEMM在CUDA中编写,库在安装期间不需要编译,通过在运行时使用轻量级的即时(JIT)模块编译所有内核。
目前DeepGEMM只支持NVIDIA Hopper tensor cores, 使用了CUDA-core two-level accumulation (promotion)
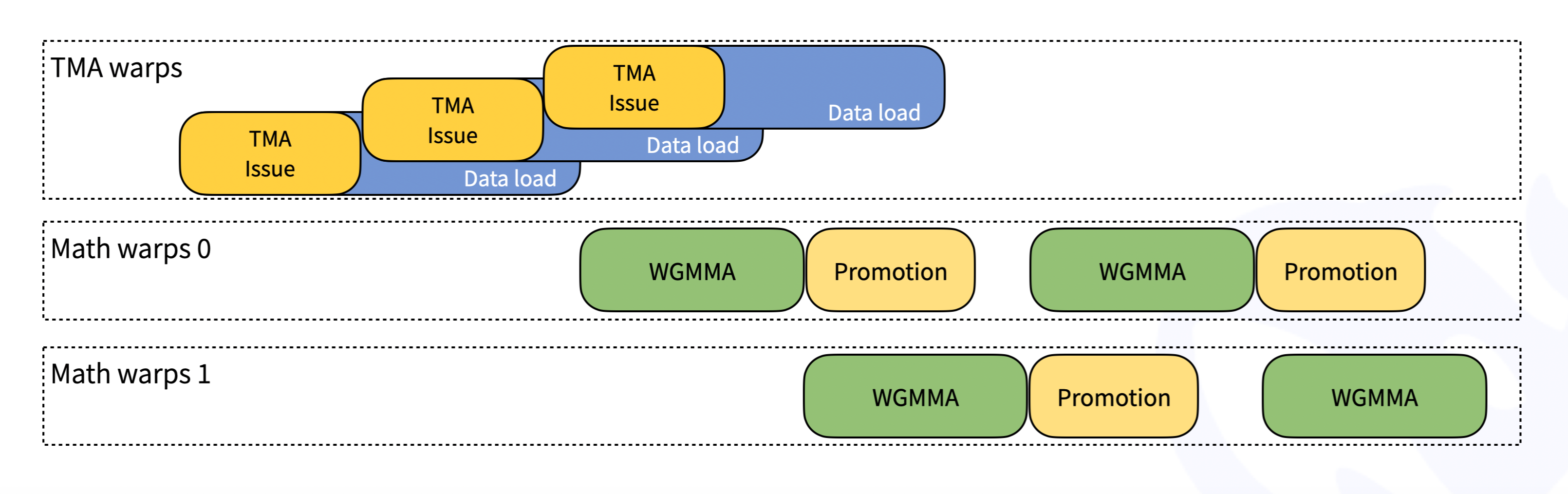
the library is designed for simplicity, with only one core kernel function comprising around ~300 lines of code.
是的, 这个功能如此强大的库, 只有大概300行的代码
Despite its lightweight design, DeepGEMM’s performance matches or exceeds expert-tuned libraries across various matrix shapes.
优雅, 且强大
八. 3FS: AI专用的高性能分布式文件系统
从单个节点的计算到多个节点的调度以及节点间的通信的优化都处理了, 但是DeepSeek的开源还没有结束.
DeepSeek在开源周的最后一天开源了针对AI场景进行设计的分布式文件系统:3FS(Fire-Flyer File System)
在幻方官网其实可以看到3FS至少从2019年就开始有了 https://www.high-flyer.cn/blog/3fs/
GitHub地址: https://github.com/deepseek-ai/3FS
Fire-Flyer File System(3FS)是一种高性能分布式文件系统,旨在解决人工智能训练和推理工作负载的挑战。它利用现代ssd和RDMA网络提供共享存储层,从而简化了分布式应用程序的开发。
Key features and benefits of 3FS include:
- Performance and Usability
- Disaggregated Architecture Combines the throughput of thousands of SSDs and the network bandwidth of hundreds of storage nodes, enabling applications to access storage resource in a locality-oblivious manner.
- Strong Consistency Implements Chain Replication with Apportioned Queries (CRAQ) for strong consistency, making application code simple and easy to reason about.
- File Interfaces Develops stateless metadata services backed by a transactional key-value store (e.g., FoundationDB). The file interface is well known and used everywhere. There is no need to learn a new storage API.
- Diverse Workloads
- Data Preparation Organizes outputs of data analytics pipelines into hierarchical directory structures and manages a large volume of intermediate outputs efficiently.
- Dataloaders Eliminates the need for prefetching or shuffling datasets by enabling random access to training samples across compute nodes.
- Checkpointing Supports high-throughput parallel checkpointing for large-scale training.
- KVCache for Inference Provides a cost-effective alternative to DRAM-based caching, offering high throughput and significantly larger capacity.
总结
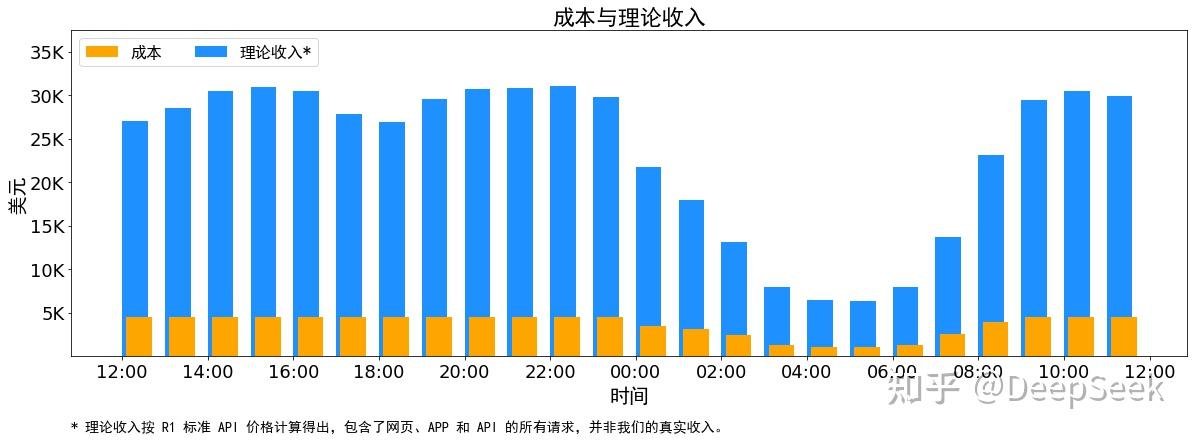
这次DeepSeek开源周开源的项目涉及了AI训练相关的方方面面, 开源周结束后发布的文章也介绍了推理系统的优化思路和简单的架构图, 给出的545%成本利润率更是给整个市场打了一个强心针, 让大家看到大模型真的能盈利, 并且盈利空间很大.
当OpenAI用GPT-4.5筑起价格高墙时,DeepSeek正用开源工具链挖开墙角